“Non nei numeri ma nell’unità sta la nostra grande forza.”
Thomas Paine
La struttura dati union del linguaggio C è di sicuro particolare e il suo reale e concreto utilizzo può essere a volte sfuggente. Come dovremmo sapere, una union è del tutto simile ad una struct con l’unica apparente differenza che di una union possiamo usare, in un dato momento, uno ed uno solo dei suoi membri. Infatti, l’occupazione di spazio di una union è relativa al massimo dello spazio occupato dal più grande dei suoi membri. Per averne una prova facciamo un esempio supponendo di avere due strutture dati: una struct e una union aventi entrambe tre membri di cui un intero, un float e un double:
#include <stdio.h>
#include <stdlib.h>
struct s
{
int i;
float f;
double d;
};
union u
{
int i;
float f;
double d;
};
int main(int argc, char *argv[])
{
struct s myStruct;
union u myUnion;
printf("\nIntero byte: %d", sizeof(myStruct.i));
printf("\nFloat byte: %d", sizeof(myStruct.f));
printf("\nDouble byte: %d", sizeof(myStruct.d));
printf("\nLa struct occupa %d byte.", sizeof(myStruct));
printf("\nLa union occupa %d byte.", sizeof(myUnion));
return 0;
}
In relazione al nostro test, prima stampiamo l’occupazione in byte dei singoli membri e poi l’occupazione delle singole strutture dati. Otterremo quanto presentato in Figura.
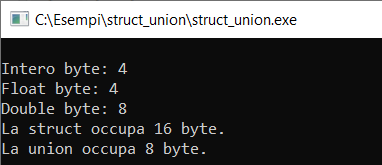
Figura: L’occupazione in byte di struct e union.
Come si evince da una immediata osservazione, la struct occupa ben 16 byte sommando, infatti, i 4 dell’intero, i 4 del float e gli 8 byte del double. Al contrario, la union occupa solo 8 byte, ovvero la dimensione del suo membro massimo, il double.
Se questo è polimorfismo
Resta comunque la domanda di fondo: ma a cosa serve una union? Ebbene, il suo scopo è di norma quello di gestire in un’unica struttura dati valori di tipo differente che riguardano una stessa variabile. In un certo senso è un tentativo del C di essere polimorfo (cosa che il C++ fa in maniera assolutamente naturale). In somma sintesi, per polimorfismo si intende la possibilità di gestire con una stessa variabile differenti tipologia di dato (un intero, un float, …) a seconda delle circostanze di nostro interesse. Vediamo allora il seguente codice in cui immaginiamo una union per gestire una sorta di variant ovvero una variabili che può assumere differenti valori a seconda di una specifica assegnazione:
#include <stdio.h>
#include <stdlib.h>
enum Type {INTEGER, FLOATS, DOUBLE};
union u
{
int i;
float f;
double d;
};
void stampa(union u *, int);
int main(int argc, char *argv[])
{
union u myVar;
int v_type; //il tipo attualmente utilizzato
v_type = INTEGER;
myVar.i = 12.66;
stampa(&myVar, v_type);
v_type = FLOATS;
myVar.f = 12.66;
stampa(&myVar, v_type);
v_type = DOUBLE;
myVar.d = 12.66;
stampa(&myVar, v_type);
return 0;
}
void stampa(union u *u, int v_type)
{
switch(v_type)
{
case INTEGER:
printf("Valore intero: %d\n", u->i);
break;
case FLOATS:
printf("Valore float: %f\n", u->f);
break;
case DOUBLE:
printf("Valore double: %lf\n", u->d);
break;
}
}
Vediamo allora di interpretare il codice in questione. Innanzitutto, definiamo la nostra union con 3 differenti membri: un intero, un float e un double.
union u
{
int i;
float f;
double d;
};
Per gestire al meglio le tre differenti situazione utilizziamo una enumerazione:
enum Type {INTEGER, FLOATS, DOUBLE};
mentre per controllare quale tipo di dato andiamo di volta in volta ad utilizzare usiamo la variabile
int v_type;
Infine, per simulare un caso reale di utilizzo sfruttiamo uno switch all’interno di una funzione di stampa:
switch(v_type)
{
case INTEGER:
printf("Valore intero: %d\n", u->i);
break;
case FLOATS:
printf("Valore float: %f\n", u->f);
break;
case DOUBLE:
printf("Valore double: %lf\n", u->d);
break;
}
Struct e union: quando l’unione fa la forza
In alcune situazioni è possibile preferire un approccio in cui l’informazione relativa al tipo di dato che vogliamo utilizzare è direttamente e strettamente collegato al dato stesso. In tali contesti è possibile integrare una union all’interno di una struct così come vi mostro di seguito:
#include <stdio.h>
#include <stdlib.h>
enum Type {INTEGER, FLOATS, DOUBLE};
struct mydata
{
int which_one;
union _value
{
int i;
float f;
double d;
} value;
};
void stampa(struct mydata *);
int main(int argc, char *argv[])
{
struct mydata x;
x.value.i =12;
x.which_one = INTEGER;
stampa(&x);
x.value.f =10.66;
x.which_one = FLOATS;
stampa(&x);
return 0;
}
void stampa(struct mydata *x)
{
switch(x->which_one)
{
case INTEGER:
printf("Valore intero: %d\n", x->value.i);
break;
case FLOATS:
printf("Valore float: %f\n", x->value.f);
break;
case DOUBLE:
printf("Valore double: %lf\n", x->value.d);
break;
}
}
Come si può scoprire dopo un primo attento esame, il punto nodale della nostra organizzazione è data dalla struct seguente:
struct mydata
{
int which_one;
union _value
{
int i;
float f;
double d;
} value;
};
La struct in questione ha innanzitutto il membro which_one che serve per tener traccia del tipo di variabile che vogliamo gestire. Anche in questo caso, così come nell’esempio precedente, usiamo la seguente enumerazione per tracciare in modo semplice il tipo di dati utilizzato in un dato momento:
enum Type {INTEGER, FLOATS, DOUBLE};
All’interno della struct abbiamo invece la nostra union con i vari tipi di variabili:
union _value
{
int i;
float f;
double d;
} value;
Per il resto il codice dovrebbe essere di relativa semplice interpretazione.
Carlo A. Mazzone