Java affonda le proprie radici nei primi anni 90 quando la rete Internet come la conosciamo oggi era ancora solo immaginazione. Così come riportato dal sito di Oracle, azienda che ora controlla lo sviluppo di Java, nel 1991, un piccolo gruppo di ingegneri della società Sun Microsystem, chiamati il Green Team immaginarono possibile realizzare di superare le differenze presenti tra differenti dispositivi digitali e computer e per farlo iniziarono lo sviluppo un nuovo linguaggio di programmazione.
Guidato da James Gosling, il Green Team entrò nella storia dell’informatica quando nel 1995 annunciò che il più diffuso browser Internet dell’epoca, Netscape Navigator, avrebbe incorporato la nuova tecnologia Java. Da notare come proprio in questo stesso anno il nome Java viene utilizzato per la prima volta andando a sostituire il primo nome scelto, ovvero Oak, a causa di problemi di copyright relativi al fatto che tale nome era già registrato dall’azienda Oak Technologies.

Figura – James Gosling con una t-shirt con la scritta “Don’t Tell the Pope” Heretical Lecture Tour – 1632.
Come molte delle storie che hanno cambiato profondamente la società, anche la storia della nascita di Java si confonde a volte con storie che sfumano nella leggenda. Tanto per dirne una sembra che il nome Oak fosse stato scelto in riferimento ad un grande albero di quercia (oak, in lingua inglese) visibile dalla finestra degli uffici di cui lavorava Gosling presso Sand Hill Road, nella città di Menlo Park in California, eletto come luogo di ritiro per il lavoro del Green Team.
Il nome Java, invece, sembra derivi da una lunga discussione per la scelta di un nuovo nome da sostituire, come detto, al nome Oak. Alla discussione parteciparono diversi membri del Green Team e tra le varie proposte di nomi, tra cui DNA, Silk, Ruby e WRL prevalse alla fine il nome Java. Sembra che l’origine del nome sia legata al fatto che uno dei membri del team, Chris Warth, stesse bevendo una tazza di Peet’s Java mentre partecipava alla discussione relativa alla scelta del nome. Java è infatti il nome di una tipologia di caffè, così come lo è quello legato al nome “espresso”. Il nome del caffè Java in realtà deriva dal fatto che esso proviene dall’isola di Giava (Java in inglese), in Indonesia, dove fu introdotto intorno al 1600 dagli olandesi. Ovviamente questo spiega anche il motivo per cui il simbolo di Java sia legato così strettamente al caffè.
![]()
Figura – Il logo del linguaggio Java.
Sempre in tema grafico, in figura è visibile la mascotte del linguaggio di nome Duke. Dettagli sulla sua nascita sono presenti a questa URL: https://www.oracle.com/java/duke.html.

Figura – Duke, la mascotte di Java.
Per quanto riguarda l’aspetto più tecnico relativo al linguaggio, la figura mostra quelle che potrebbero essere considerate le radici di Java che, come si può osservare, derivano da una parte dallo storico linguaggio Smalltalk di fedele osservazione dei principi della programmazione orientata agli oggetti e dall’altra dal mitico linguaggio C. Il tutto passa attraverso il C++ già, anch’esso, con una spiccata declinazione verso il paradigma di programmazione ad oggetti.
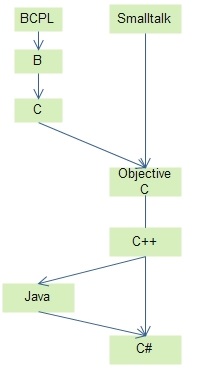
Figura – Le origini di Java.
Carlo A. Mazzone

 Uno degli approcci più classici nello sviluppo software è quello che prende il nome di programmazione procedurale. In buon sostanza di tratta della pratica di suddividere il programma principale in parti più piccole, note con il termine di sottoprogrammi (in inglese subroutine) ma anche procedure o funzioni a seconda dei diversi linguaggi di programmazione. Tutto ciò per facilitare la stesura e la manutenzione del programma stesso. Dopo questa introduzione sui sottoprogrammi dareste per scontato la loro disponibilità nei file batch. Ebbene, sbagliereste, in quanto tale possibilità non è contemplata nei file batch. Tuttavia, una possibilità di emulare tale comportamento è comunque possibile individuarla, innanzitutto nell’utilizzo del comando CALL che consente di richiamare un altro file batch. Supponiamo allora di avere un file batch di esempio che serve solo a produrre un messaggio a video:
Uno degli approcci più classici nello sviluppo software è quello che prende il nome di programmazione procedurale. In buon sostanza di tratta della pratica di suddividere il programma principale in parti più piccole, note con il termine di sottoprogrammi (in inglese subroutine) ma anche procedure o funzioni a seconda dei diversi linguaggi di programmazione. Tutto ciò per facilitare la stesura e la manutenzione del programma stesso. Dopo questa introduzione sui sottoprogrammi dareste per scontato la loro disponibilità nei file batch. Ebbene, sbagliereste, in quanto tale possibilità non è contemplata nei file batch. Tuttavia, una possibilità di emulare tale comportamento è comunque possibile individuarla, innanzitutto nell’utilizzo del comando CALL che consente di richiamare un altro file batch. Supponiamo allora di avere un file batch di esempio che serve solo a produrre un messaggio a video: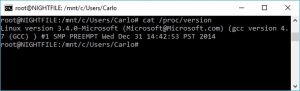 Oltre alla soluzione che prevede l’installazione di Cygwin (https://www.cygwin.com/) come ambiente di emulazione per Linux, per i sistemi Windows 10 esiste un’alternativa che prevede l’installazione della shell bash come applicativo nativo di Windows stesso. La bash su Windows fornisce così agli sviluppatori e sistemisti una shell Linux in cui eseguire la maggior parte dei comandi Linux senza dover installare uno specifico emulatore esterno. Il prerequisito fondamentale per l’installazione di tale bash è che il nostro Windows sia una versione a 64-bit Anniversary Update build 14393 o superiore. Per verificare la versione del sistema in uso è sufficiente e l’architettura della CPU della nostra macchina è sufficiente accedere a Impostazioni->Sistema-> Informazioni su.
Oltre alla soluzione che prevede l’installazione di Cygwin (https://www.cygwin.com/) come ambiente di emulazione per Linux, per i sistemi Windows 10 esiste un’alternativa che prevede l’installazione della shell bash come applicativo nativo di Windows stesso. La bash su Windows fornisce così agli sviluppatori e sistemisti una shell Linux in cui eseguire la maggior parte dei comandi Linux senza dover installare uno specifico emulatore esterno. Il prerequisito fondamentale per l’installazione di tale bash è che il nostro Windows sia una versione a 64-bit Anniversary Update build 14393 o superiore. Per verificare la versione del sistema in uso è sufficiente e l’architettura della CPU della nostra macchina è sufficiente accedere a Impostazioni->Sistema-> Informazioni su. In un sistema Linux, capita molto spesso di dover eseguire un certo file, un particolare comando oppure una serie di operazioni in uno specifico momento della giornata. Un caso classico è rappresentato da operazioni di backup dei dati da effettuarsi preferibilemente in orario notturno.
In un sistema Linux, capita molto spesso di dover eseguire un certo file, un particolare comando oppure una serie di operazioni in uno specifico momento della giornata. Un caso classico è rappresentato da operazioni di backup dei dati da effettuarsi preferibilemente in orario notturno. “Il potere del comando”, l’ultimo libro di Carlo A. Mazzone, diventa anche cartaceo. Dopo una prima distribuzione in formato eBook, infatti, questa guida alle interfacce testuali viene ora stampata su carta e distribuita sui principali store online.
“Il potere del comando”, l’ultimo libro di Carlo A. Mazzone, diventa anche cartaceo. Dopo una prima distribuzione in formato eBook, infatti, questa guida alle interfacce testuali viene ora stampata su carta e distribuita sui principali store online. Può essere interessante in ambito laboratoriale o di sviluppo all’interno di un dato gruppo di lavoro abilitare su di una macchina Linux con web server Apache la possibilità per i singoli account utente di utilizzare una specifica cartella per i propri file html e php.
Può essere interessante in ambito laboratoriale o di sviluppo all’interno di un dato gruppo di lavoro abilitare su di una macchina Linux con web server Apache la possibilità per i singoli account utente di utilizzare una specifica cartella per i propri file html e php. E’ esigenza diffusa realizzare copie di sicurezza di file personali e/o aziendali su una macchina diversa da quella in cui risiedono i file stessi. In questo micro post vi riporto un semplice script da utilizzarsi su macchine windows verso uno sharing di rete che può essere ospitato tanto su di un server Windows tanto su di una macchina Linux con server Samba.
E’ esigenza diffusa realizzare copie di sicurezza di file personali e/o aziendali su una macchina diversa da quella in cui risiedono i file stessi. In questo micro post vi riporto un semplice script da utilizzarsi su macchine windows verso uno sharing di rete che può essere ospitato tanto su di un server Windows tanto su di una macchina Linux con server Samba.