Questa mini guida illustra in maniera sintetica e diretta le modalità di preparazione di un sistema Raspberry.
Installazione di Raspbian con NOOBS
L’uso di NOOBS rappresenta il modo più facile per installare Raspbian su di una SD card. NOOBS, ovvero New Out Of Box Software, è un manager di installazione per i sistemi operativi compatibili con la Raspberry Pi. NOOBS è disponibile in due tipologie: offline e network install (versione Full)oppure solo network install (versione Lite).
La versione full include già Raspbian in modo che la si possa installare,direttamente sulla SD card, mentre la versione Lite di NOOBS necessità sempre di una connessione a internet per installare sua Raspian che un qualsiasi altro sistema operativo.
Ovviamente, la versione già presente del sistema operativo sulla versione full potrebbe essere non aggiornata nel caso un cui un un nuovo sistema dovesse essere stato appena rilasciato ma connettendosi ad Internet verranno mostrate le opzioni per il download dell’ultima versione eventualmente disponibile.
Download di NOOBS
L’URL di riferimento per lo scaricamento di una copia di NOOBS è:
www.raspberrypi.org/downloads/
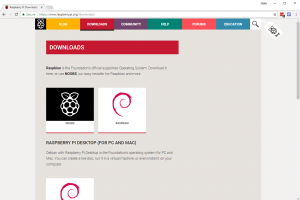
Una volta raggiunta la pagina in questione cliccare sul link relativo a NOOBS.

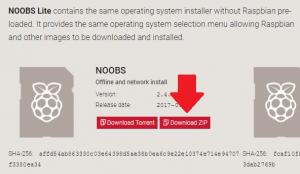
A questo punto selezionare, per semplicità, l’opzione per lo scaricamento dello zip (o in alternativa usare un programma per il download dei file torrent).
Formattazione della SD Card
A questo punto sarà necessario preparare la scheda SD. Poichè la procedura prevede la cancellazione totale dei file presenti sulla scheda, se ritenuto opportuno, sarà necessario effettuare un backup dei dati eventualmente presenti.
In generale, la formattazione della scheda può essere realizzata con gli strumenti classici presenti nel sistema operativo. Tuttavia, tali strumenti non sono ottimizzati per le schede SD/SDHC/SDXC e ciò potrebbe comportare delle performance più basse.
Il consiglio è quindi quello di utilizzare uno strumento appositamente progettato per tale scopo, ovvero il “SD Memory Card Formatter 5.0 for SD/SDHC/SDXC” disponibile per il download, per Windows e Mac, qui:
https://www.sdcard.org/downloads/formatter_4/index.html
Sarà sufficiente seguire le istruzioni per il download e l’installazione del software e successivamente inserire la SD card nel proprio PC o laptop. Nel Formatter selezionare la lettera assegnata alla SD card e procedere con la formattazione.
Estrazione e copia di NOOBS
Ovviamente è ora necessario estrarre i file dallo zip NOOBS. Per farlo usate la vostra procedura preferita.
A questo punto utilizzando Explorer (per Windows) oppure il Finder (per Mac) spostatevi nella cartella dove è stato estratto lo zip. Sarà ora sufficiente farne il drag and drop oppure un copia e incolla nella radice della SD card.
A questo punto non resta che estrarre la scheda SD.
Avvio di NOOBS
Una volta copiati i file di NOOBS sulla micro SD Card sarà sufficiente inserire la scheda nella Raspberry Pi e collegarla all’alimentazione.
Una volta avviato il sistema potrete selezionare il box per il sistema Raspbian e quindi cliccare sula voce Install.
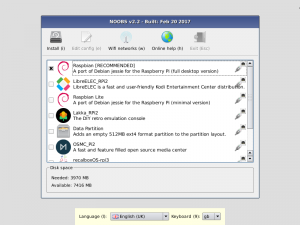
NOTA: L’utente di default in Raspbian è pi, e la corrispondente password, necessaria per scopi di amministrazione, è raspberry.
La cosa interessante da sapere è che l’elenco dei sistemi operativi disponibili per l’installazione, se non precedentemente installati, viene visualizzato solo nel caso in cui la Raspeberry sia collegata alla rete (via cavo o wireless). Nel caso di collegamento fisico con cavo la Raspberry ottiene un IP tramite DHCP mentre nel caso di collegamento wireless è necessario impostare i parametri della scheda tramite l’apposita icona relativa alla rete Wi-Fi.
Al riavvio della scheda è sempre possibile scegliere un nuovo sistema operativo da installare premendo il tasto Shift.
di Carlo A. Mazzone (Ver. 20180121A)
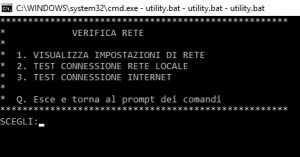 Uno degli approcci più classici nello sviluppo software è quello che prende il nome di programmazione procedurale. In buon sostanza di tratta della pratica di suddividere il programma principale in parti più piccole, note con il termine di sottoprogrammi (in inglese subroutine) ma anche procedure o funzioni a seconda dei diversi linguaggi di programmazione. Tutto ciò per facilitare la stesura e la manutenzione del programma stesso. Dopo questa introduzione sui sottoprogrammi dareste per scontato la loro disponibilità nei file batch. Ebbene, sbagliereste, in quanto tale possibilità non è contemplata nei file batch. Tuttavia, una possibilità di emulare tale comportamento è comunque possibile individuarla, innanzitutto nell’utilizzo del comando CALL che consente di richiamare un altro file batch. Supponiamo allora di avere un file batch di esempio che serve solo a produrre un messaggio a video:
Uno degli approcci più classici nello sviluppo software è quello che prende il nome di programmazione procedurale. In buon sostanza di tratta della pratica di suddividere il programma principale in parti più piccole, note con il termine di sottoprogrammi (in inglese subroutine) ma anche procedure o funzioni a seconda dei diversi linguaggi di programmazione. Tutto ciò per facilitare la stesura e la manutenzione del programma stesso. Dopo questa introduzione sui sottoprogrammi dareste per scontato la loro disponibilità nei file batch. Ebbene, sbagliereste, in quanto tale possibilità non è contemplata nei file batch. Tuttavia, una possibilità di emulare tale comportamento è comunque possibile individuarla, innanzitutto nell’utilizzo del comando CALL che consente di richiamare un altro file batch. Supponiamo allora di avere un file batch di esempio che serve solo a produrre un messaggio a video: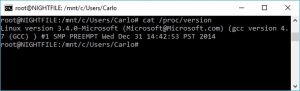 Oltre alla soluzione che prevede l’installazione di Cygwin (https://www.cygwin.com/) come ambiente di emulazione per Linux, per i sistemi Windows 10 esiste un’alternativa che prevede l’installazione della shell bash come applicativo nativo di Windows stesso. La bash su Windows fornisce così agli sviluppatori e sistemisti una shell Linux in cui eseguire la maggior parte dei comandi Linux senza dover installare uno specifico emulatore esterno. Il prerequisito fondamentale per l’installazione di tale bash è che il nostro Windows sia una versione a 64-bit Anniversary Update build 14393 o superiore. Per verificare la versione del sistema in uso è sufficiente e l’architettura della CPU della nostra macchina è sufficiente accedere a Impostazioni->Sistema-> Informazioni su.
Oltre alla soluzione che prevede l’installazione di Cygwin (https://www.cygwin.com/) come ambiente di emulazione per Linux, per i sistemi Windows 10 esiste un’alternativa che prevede l’installazione della shell bash come applicativo nativo di Windows stesso. La bash su Windows fornisce così agli sviluppatori e sistemisti una shell Linux in cui eseguire la maggior parte dei comandi Linux senza dover installare uno specifico emulatore esterno. Il prerequisito fondamentale per l’installazione di tale bash è che il nostro Windows sia una versione a 64-bit Anniversary Update build 14393 o superiore. Per verificare la versione del sistema in uso è sufficiente e l’architettura della CPU della nostra macchina è sufficiente accedere a Impostazioni->Sistema-> Informazioni su. In un sistema Linux, capita molto spesso di dover eseguire un certo file, un particolare comando oppure una serie di operazioni in uno specifico momento della giornata. Un caso classico è rappresentato da operazioni di backup dei dati da effettuarsi preferibilemente in orario notturno.
In un sistema Linux, capita molto spesso di dover eseguire un certo file, un particolare comando oppure una serie di operazioni in uno specifico momento della giornata. Un caso classico è rappresentato da operazioni di backup dei dati da effettuarsi preferibilemente in orario notturno. “Il potere del comando”, l’ultimo libro di Carlo A. Mazzone, diventa anche cartaceo. Dopo una prima distribuzione in formato eBook, infatti, questa guida alle interfacce testuali viene ora stampata su carta e distribuita sui principali store online.
“Il potere del comando”, l’ultimo libro di Carlo A. Mazzone, diventa anche cartaceo. Dopo una prima distribuzione in formato eBook, infatti, questa guida alle interfacce testuali viene ora stampata su carta e distribuita sui principali store online. Può essere interessante in ambito laboratoriale o di sviluppo all’interno di un dato gruppo di lavoro abilitare su di una macchina Linux con web server Apache la possibilità per i singoli account utente di utilizzare una specifica cartella per i propri file html e php.
Può essere interessante in ambito laboratoriale o di sviluppo all’interno di un dato gruppo di lavoro abilitare su di una macchina Linux con web server Apache la possibilità per i singoli account utente di utilizzare una specifica cartella per i propri file html e php. E’ esigenza diffusa realizzare copie di sicurezza di file personali e/o aziendali su una macchina diversa da quella in cui risiedono i file stessi. In questo micro post vi riporto un semplice script da utilizzarsi su macchine windows verso uno sharing di rete che può essere ospitato tanto su di un server Windows tanto su di una macchina Linux con server Samba.
E’ esigenza diffusa realizzare copie di sicurezza di file personali e/o aziendali su una macchina diversa da quella in cui risiedono i file stessi. In questo micro post vi riporto un semplice script da utilizzarsi su macchine windows verso uno sharing di rete che può essere ospitato tanto su di un server Windows tanto su di una macchina Linux con server Samba. La presente brevissima guida descrive in estrema sintesi l’installazione e configurazione di un server DHCP su di una macchina Linux Ubuntu. Come dovrebbe essere noto il DHCP, ovvero Dynamic Host Configuration Protocol, è un protocollo di rete utilizzato per configurare in maniera dinamica, potremmo dire “al volo”, le schede di rete al fine di minimizzare gli sforzi necessari per manutenere configurazioni di tipo statico. In soldoni, invece di definire manualmente l’indirizzo IP, la netmask, il gateway di default, DNS, ecc. ecc. necessari per consentire alla specifica macchina di “navigare” in rete, demandiamo il tutto al server DHCP. E’ intuitivo riflettere sull’utilità di tale approccio soprattutto quando i dispositivi in questione sono di tipo mobile.
La presente brevissima guida descrive in estrema sintesi l’installazione e configurazione di un server DHCP su di una macchina Linux Ubuntu. Come dovrebbe essere noto il DHCP, ovvero Dynamic Host Configuration Protocol, è un protocollo di rete utilizzato per configurare in maniera dinamica, potremmo dire “al volo”, le schede di rete al fine di minimizzare gli sforzi necessari per manutenere configurazioni di tipo statico. In soldoni, invece di definire manualmente l’indirizzo IP, la netmask, il gateway di default, DNS, ecc. ecc. necessari per consentire alla specifica macchina di “navigare” in rete, demandiamo il tutto al server DHCP. E’ intuitivo riflettere sull’utilità di tale approccio soprattutto quando i dispositivi in questione sono di tipo mobile.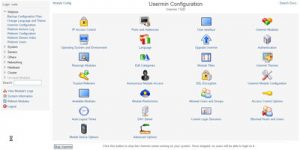 La prima volta che feci conoscenza con il pacchetto Usermin fu quando ero in cerca di un sistema per consentire agli utenti, gestiti tramite una macchina Linux, di poter cambiare la propria password senza costringerli all’uso della shell testuale tramite un brutale passwd.
La prima volta che feci conoscenza con il pacchetto Usermin fu quando ero in cerca di un sistema per consentire agli utenti, gestiti tramite una macchina Linux, di poter cambiare la propria password senza costringerli all’uso della shell testuale tramite un brutale passwd.