Di seguito una revisione di un articolo già pubblicato relativo alla versione Ubuntu 7.04.
Hope this helps.
 Qualsiasi programmatore che abbia sviluppato in team con altri sviluppatori si sarà reso conto della necessità di condividere pezzi di codice con gli altri elementi del gruppo e delle difficoltà legate a tale condivisione. Fortunatamente esistono software appositamente progettati per consentire a differenti sviluppatori di lavorare sugli stessi progetti controllando le modifiche apportate ed evitando sovrascritture accidentali degli stessi frammenti di codice.
Qualsiasi programmatore che abbia sviluppato in team con altri sviluppatori si sarà reso conto della necessità di condividere pezzi di codice con gli altri elementi del gruppo e delle difficoltà legate a tale condivisione. Fortunatamente esistono software appositamente progettati per consentire a differenti sviluppatori di lavorare sugli stessi progetti controllando le modifiche apportate ed evitando sovrascritture accidentali degli stessi frammenti di codice.
Oltre al classico “SourceSafe” prodotto dalla Microsoft ed agli strumenti messi a disposizione nell’ultima, e molto costosa, suite Microsoft Visual Studio Team Edition, ha preso piede in questi ultimi tempi un sistema gratuito e molto affidabile chiamato SubVersion. Tale software sembra stia soppiantando nei gusti dei sistemi un po’ di tutto il mondo un software analogo di nome CVS (Concurrent Versions System) dal quale SubVersion prende le mosse.
In questo articolo vediamo come installare la parte server di SubVersion su di una distribuzione Linux Ubuntu. Nello specifico il tutto è stato provato con la versione 11.10.
Si presuppone che sul sistema sia installato Apache 2.
Il pacchetto indispensabile per subversion è semplicemetne “subversion”
Per cui procediamo alla sua installazione utilizzando il comando apt-get:
$ sudo apt-get install subversion
Il comando provvederà ad installare i moduli necessari, SubVersion e SVN per Apache.
Il modulo SVN dovrebbe essere automaticamente abilitato dopo l’installazione. Se così non fosse è possibile utilizzare il comando “a2enmod”, uno script che abilita il modulo specificato, ad esempio, nel nostro caso:
$ sudo a2enmod dav_svn
Incidentalmente faccio notare che esiste un comando con funzione opposta, vale a dire per disabilitare un modulo: “a2dismod [nome modulo]”
CREAZIONE DEL REPOSITORY SVN
Installeremo il repository in /svn
Creiamo come prima cosa il gruppo ‘subversion’
$ sudo groupadd subversion
Aggiungiamo l’utente Apache, ovvero www-data, al gruppo subversion appena creato.
$ sudo usermod -G subversion www-data
Da notare come con il comando $ groups www-data sia possibile verificare il successo del comando precedente.
Passiamo ora alla creazione della cartelle fisiche sul file system per i repository:
$ sudo mkdir /home/svn
Spostiamoci nella cartella appena creata e creaiamo una ulteriore nuova cartella per il nostro primo progetto:
$ cd /home/svn
$ sudo mkdir tesseract
A questo punto passo alla creazione dle repository vero e proprio
$ sudo svnadmin create /home/svn/tesseract
Passiamo ora alla corretta impostazion dei permessi:
$ cd /home/svn
$ sudo chown -R www-data:subversion tesseract
Dove, con l’ultimo comando, impostiamo per la cartella ‘tesseract’ ed in maniera ricorsiva per tutte le sottocartelle come prorietrartio l’utente ‘www-data’ e come gruppo ‘subversion’
Ed infine:
$ sudo chmod -R g+rws tesseract
Per abilitare lettura e scrittura (rw) per il gruppo. Da notare il flag ‘s’. Questo, detto di norma setuid e’ necessario in quanto svnadmin deve creare i file durante operazioni tipo commit.
CONFIGURARE L’ACCESSO A SVN
I repository di SVN possono essere gestiti tramite vari protocolli (file, http, https, svn+ssh, …). Sicuramente, il piu’ semplice è l’accesso via protocollo WebDAV (http://).
Per utilizzare questo protocollo è necessario configurare correttamente Apache. Si presuppone quindi l’installazione del pacchetto libapache2-svn:
$ sudo apt-get install libapache2-svn
Sarebbe possibile apportare le modifiche del caso al file /etc/apache2/mods-enabled/dav_svn.conf, tuttavia ciò non è possibile nel caso di configurazione sulla macchina server di hosts virtuali (vhosts).
E’ questa la tipologia di configurazione che personalemtne prediligo per cui suggerisco la modifica dei file in /etc/apache2/sites-available/*
La cartella “/etc/apache2/sites-available/” contiene un file di configurazione per ogni sito virtuale disponibile sulla macchina. Ne esiste uno predefinito, con nome “default”. E’ possibile modificare direttamente questo file con le opportune proprie “customizzazioni” e, nel caso sia necessario rendere disponibile un nuovo sito virtuale, è possibile duplicare il file in questione (utilizzando un nome a piacimento) e modificarlo seconda necessità.
La cartella in questione elenca, come dice il nome stesso, i siti disponibili sulla macchina. Essere disponibile non è sufficiente: bisogna anche che il sito sia abilitato. A tale scopo esiste una utility “a2ensite” che abilita il sito specificato. Ciò che tale utility realizza è la creazione di un link simbolico nella cartella /etc/apache2/sites-enabled/ che punta al file di configurazione del sito specificato. Un utility complementare, “a2dissite”, consente di disabilitare momentaneamente uno specifico sito senza costringere a cancellare o rinominare il file di configurazione.
La lettura dei file “enabled”, cioè abilitati, è resa possibile dalla direttiva:
“Include /etc/apache2/sites-enabled/”
presente nel file di configurazione principale di Apache.
Un tipico file di configurazione di un host sarà qualcosa del tipo:
<VirtualHost 192.168.1.1:80>
DocumentRoot /home/test/public_html
ServerName nomesito.tesseract.it
<Location /svntest>
DAV svn
SVNListParentPath on
SVNPath /home/test/repositories/test1
AuthType Basic
AuthName “Tesseract SVN test repository”
AuthUserFile /etc/apache2/users
AuthGroupFile /etc/apache2/groups
Require group developers
</Location>
</VirtualHost>
Da notare che dovranno essere presenti nel file di configurazione generale (apache2.conf) le seguenti righe:
NameVirtualHost 192.168.1.1:80
Dove 192.168.1.1 è l’IP della vostra macchina server
Include /etc/apache2/sites-enabled/
Per includere i file di configurazione degli host virtuali.
Per aggiornare il server al nuovo stato dare il comando:
sudo /etc/init.d/apache2 reload
APACHE E IL CONTROLLO DEGLI UTENTI
Per memorizzare le informazioni relative agli utenti e relative password per l’accesso ai contenuti è necessario creare un apposito file.
Tale file, per ovvie ragioni di sicurezza, deve essere registrato in una posizione tale da non essere accessibile da web. Esso, inoltre, non può essere editato direttamente a mano; le password, infatti, sono registrate in forma cifrata.
Il programma utilizzato per tale gestione è “htpasswd”:
Per iniziare è necessario creare il file in questione indicando un primo nuovo utente da inserire nel file stesso:
htpasswd -c /etc/apache2/users carlo
Il comando, con l’opzione -c, crea il file “users” nella directory /etc/apache2/ chiedendo la password da associare all’utente (nel nostro caso, l’utente “carlo”).
Il contenuto del file “users” dovrebbe essere ora simile al seguente:
——————————————-
carlo: xx1LtcDbOY4/K
——————————————-
dove si individua il primo campo contenente il nome utente ed il secondo campo, separato dal simbolo “:” contenente la password in forma cifrata.
Per inserire nuovi utenti all’interno del file riusiamo il comando htpasswd, omettendo ovviamente il flag -c in quanto il file è stato già creato; ad esempio, il comando:
——————————————-
htpasswd /etc/apache2/users giuseppe
——————————————-
aggiunge al file /etc/apache2/users l’utente “giuseppe”
Nella sezione “<Location></Location>” si utilizzano una serie di direttive per configurare i contenuti del repository ed i relativi accessi.
Vediamo in dettaglio le principali tra tali direttive:
SVNPath valorizzato nel nostr caso con il percorso “/home/test/repositories/test1” indica, appunto, il percorso fisico del repository. Tale percorso viene raggiunto tramite la redirezione impostata con “<Location /svntest>”.
In concreto l’URL http://nomeMacchina/svntest redirigerà il browser nel repository specificato dal valore impostato in “SVNPath”.
AuthName indica un nome per la zona, ovvero l’insieme di file e cartelle, per le quali si vuole controllare l’accesso. Esso rappresenta quello che in gergo tecnico viene definito “realm”. Un realm rappresenta, appunto, una zona del file system, generalmente una directory con eventuali sottodirectory che si intende proteggere. Una volta avvenuta l’autenticazione relativamente ad un certo realm questa viene conservata per la sessione corrente e sarà valida anche in una zona differente purchè avente lo stesso nome di realm.
AuthType indica il protocollo da utilizzarsi per l’autenticazione. Basic è quello predefinito.
AuthUserFile indica al server il nome e la posizione del file da contenente le credenziali di accesso.
Nel caso si volessero usare dei gruppi, anzichè gestire il singolo utente, è possibile utilizzare la direttiva AuthGroupFile
require indica gli utenti che possono avere accesso al realm specificato: Nel caso si voglia abilitare tutti gli utenti indicati nel file delle password è sufficiente valorizzare la direttiva require con il valore valid-user.
In caso contrario, nel caso si volesse autorizzare un sottoinsieme di utenti sarà sufficiente indicare i loro nomi dopo la direttiva stessa. Ad esempio:
require user carlo giuseppe
abilita all’accesso i soli utenti “carlo” e “giuseppe”
Nel caso di situazioni più complesse è possibile ricorrere alla gestione dei gruppi utilizzardo la direttiva AuthGroupFile e specificando il file contenente le informazioni sui gruppi stessi. Un file di tale tipo è organizzato in una sequenza di righe contenenti i nomi dei gruppi e, separati dal sibolo “:”, l’elenco degli utenti appartenenti allo specifico gruppo:
amministratori:carlo giuseppe
segreteria:anna isabella antonella
Per l’autenticazione si può poi procedere, ad esempio, come segue:
require group amministratori segreteria
require user carlotta
Tali direttive abilitano, dopo l’inserimento delle giuste credenziali, gli utenti dei gruppi “amministratori” e “segreteria” e l’utente “carlotta”, all’accesso alle risorse del realm.
Il client di accesso a SubVersion
Come client è possibile usare TortoiseSVN (http://tortoisesvn.net). Si tratta di un software gratuito per Windows che si integra perfettamente in “gestione risorse”.
Carlo Mazzone
www.tesseract.it
Supportaci condividendo sui social il nostro articolo!
 “Il potere del comando”, l’ultimo libro di Carlo A. Mazzone, diventa anche cartaceo. Dopo una prima distribuzione in formato eBook, infatti, questa guida alle interfacce testuali viene ora stampata su carta e distribuita sui principali store online.
“Il potere del comando”, l’ultimo libro di Carlo A. Mazzone, diventa anche cartaceo. Dopo una prima distribuzione in formato eBook, infatti, questa guida alle interfacce testuali viene ora stampata su carta e distribuita sui principali store online. Può essere interessante in ambito laboratoriale o di sviluppo all’interno di un dato gruppo di lavoro abilitare su di una macchina Linux con web server Apache la possibilità per i singoli account utente di utilizzare una specifica cartella per i propri file html e php.
Può essere interessante in ambito laboratoriale o di sviluppo all’interno di un dato gruppo di lavoro abilitare su di una macchina Linux con web server Apache la possibilità per i singoli account utente di utilizzare una specifica cartella per i propri file html e php. E’ esigenza diffusa realizzare copie di sicurezza di file personali e/o aziendali su una macchina diversa da quella in cui risiedono i file stessi. In questo micro post vi riporto un semplice script da utilizzarsi su macchine windows verso uno sharing di rete che può essere ospitato tanto su di un server Windows tanto su di una macchina Linux con server Samba.
E’ esigenza diffusa realizzare copie di sicurezza di file personali e/o aziendali su una macchina diversa da quella in cui risiedono i file stessi. In questo micro post vi riporto un semplice script da utilizzarsi su macchine windows verso uno sharing di rete che può essere ospitato tanto su di un server Windows tanto su di una macchina Linux con server Samba. La presente brevissima guida descrive in estrema sintesi l’installazione e configurazione di un server DHCP su di una macchina Linux Ubuntu. Come dovrebbe essere noto il DHCP, ovvero Dynamic Host Configuration Protocol, è un protocollo di rete utilizzato per configurare in maniera dinamica, potremmo dire “al volo”, le schede di rete al fine di minimizzare gli sforzi necessari per manutenere configurazioni di tipo statico. In soldoni, invece di definire manualmente l’indirizzo IP, la netmask, il gateway di default, DNS, ecc. ecc. necessari per consentire alla specifica macchina di “navigare” in rete, demandiamo il tutto al server DHCP. E’ intuitivo riflettere sull’utilità di tale approccio soprattutto quando i dispositivi in questione sono di tipo mobile.
La presente brevissima guida descrive in estrema sintesi l’installazione e configurazione di un server DHCP su di una macchina Linux Ubuntu. Come dovrebbe essere noto il DHCP, ovvero Dynamic Host Configuration Protocol, è un protocollo di rete utilizzato per configurare in maniera dinamica, potremmo dire “al volo”, le schede di rete al fine di minimizzare gli sforzi necessari per manutenere configurazioni di tipo statico. In soldoni, invece di definire manualmente l’indirizzo IP, la netmask, il gateway di default, DNS, ecc. ecc. necessari per consentire alla specifica macchina di “navigare” in rete, demandiamo il tutto al server DHCP. E’ intuitivo riflettere sull’utilità di tale approccio soprattutto quando i dispositivi in questione sono di tipo mobile. La prima volta che feci conoscenza con il pacchetto Usermin fu quando ero in cerca di un sistema per consentire agli utenti, gestiti tramite una macchina Linux, di poter cambiare la propria password senza costringerli all’uso della shell testuale tramite un brutale passwd.
La prima volta che feci conoscenza con il pacchetto Usermin fu quando ero in cerca di un sistema per consentire agli utenti, gestiti tramite una macchina Linux, di poter cambiare la propria password senza costringerli all’uso della shell testuale tramite un brutale passwd.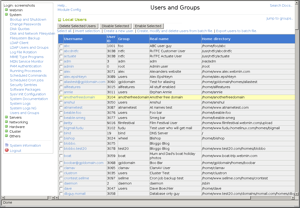 Webmin è un utilissimo strumento di amministrazione per server Linux. Esso consente tramite un semplice accesso via web di configurare ed amministrare svariati servizi: apache, dns, dhcp solo per citarne alcuni. Webmin consente inoltre di gestire account e lavorare sul file system del server sul quale è installato. Ma anche questo è un elenco estremamente riduttivo delle sue possibilità. In definitiva in un solo ambiente è possibile avere sotto le proprie dita un intero sistema server.
Webmin è un utilissimo strumento di amministrazione per server Linux. Esso consente tramite un semplice accesso via web di configurare ed amministrare svariati servizi: apache, dns, dhcp solo per citarne alcuni. Webmin consente inoltre di gestire account e lavorare sul file system del server sul quale è installato. Ma anche questo è un elenco estremamente riduttivo delle sue possibilità. In definitiva in un solo ambiente è possibile avere sotto le proprie dita un intero sistema server. E’ possibile rendere più fine il controllo degli accessi sui repository di SVN che utilizzano Apache 2 rispetto alle impostazioni standard che prevedono che un utente possa semplicemente accedere in lettura e scrittura ad uno specifico repository nella sua globalità.
E’ possibile rendere più fine il controllo degli accessi sui repository di SVN che utilizzano Apache 2 rispetto alle impostazioni standard che prevedono che un utente possa semplicemente accedere in lettura e scrittura ad uno specifico repository nella sua globalità. La presente procedura consente la realizzazione di un hotspot wireless basato su di una macchina Linux ed il demone hostapd (http://w1.fi/hostapd/).
La presente procedura consente la realizzazione di un hotspot wireless basato su di una macchina Linux ed il demone hostapd (http://w1.fi/hostapd/).